嘉定區正規驗證模型優勢
模型驗證:確保AI系統準確性與可靠性的關鍵步驟在人工智能(AI)領域,模型驗證是確保機器學習模型在實際應用中表現良好、準確且可靠的關鍵環節。隨著AI技術的飛速發展,從自動駕駛汽車到醫療診斷系統,各種AI應用正日益融入我們的日常生活。然而,這些應用的準確性和安全性直接關系到人們的生命財產安全,因此,對模型進行嚴格的驗證顯得尤為重要。一、模型驗證的定義與目的模型驗證是指通過一系列方法和流程,系統地評估機器學習模型的性能、準確性、魯棒性、公平性以及對未見數據的泛化能力。其**目的在于:將驗證和優化后的模型部署到實際應用中。嘉定區正規驗證模型優勢
選擇合適的評估指標:根據具體的應用場景和需求,選擇合適的評估指標來評估模型的性能。常用的評估指標包括準確率、召回率、F1分數等。多次驗證:為了獲得更可靠的驗證結果,可以進行多次驗證并取平均值作為**終評估結果。考慮模型復雜度:在驗證過程中,需要權衡模型的復雜度和性能。過于復雜的模型可能導致過擬合,而過于簡單的模型可能無法充分捕捉數據中的信息。綜上所述,模型驗證是確保模型性能穩定、準確的重要步驟。通過選擇合適的驗證方法、遵循規范的驗證步驟和注意事項,可以有效地評估和改進模型的性能。寶山區正規驗證模型優勢驗證過程可以幫助我們識別和減少過擬合的風險。

模型驗證:交叉驗證:如果數據量較小,可以采用交叉驗證(如K折交叉驗證)來更***地評估模型性能。性能評估:使用驗證集評估模型的性能,常用的評估指標包括準確率、召回率、F1分數、均方誤差(MSE)、均方根誤差(RMSE)等。超參數調優:通過網格搜索、隨機搜索等方法調整模型的超參數,找到在驗證集上表現比較好的參數組合。模型測試:使用測試集對**終確定的模型進行測試,確保模型在未見過的數據上也能保持良好的性能。比較測試集上的性能指標與驗證集上的性能指標,以驗證模型的泛化能力。模型解釋與優化:
交叉驗證:交叉驗證是一種常用的內部驗證方法,它將數據集拆分為多個相等大小的子集,然后重復進行模型構建和驗證的步驟。每次選用其中的一個子集用于評估模型性能,其他所有的子集用來構建模型。這種方法可以確保模型驗證時使用的數據是模型擬合過程中未使用的數據,從而提高驗證的可靠性。Bootstrapping法:在這種方法中,原始數據集被隨機抽樣數百次(有放回)用來創建相同大小的多個數據集。然后,在這些數據集上分別構建模型并評估性能。這種方法可以提供對模型性能的穩健估計。將不同模型的性能進行比較,選擇表現模型。
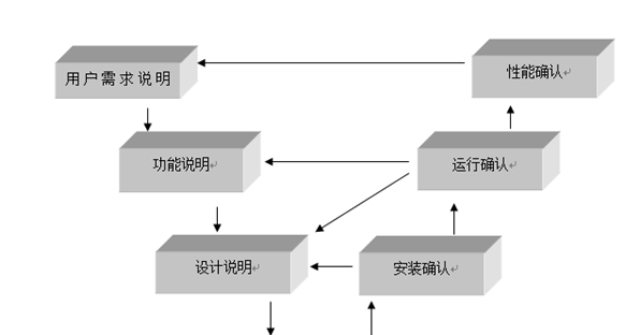
模型驗證是機器學習和統計建模中的一個重要步驟,旨在評估模型的性能和可靠性。通過模型驗證,可以確保模型在未見數據上的泛化能力。以下是一些常見的模型驗證方法和步驟:數據劃分:訓練集:用于訓練模型。驗證集:用于調整模型參數和選擇模型。測試集:用于**終評估模型性能,確保模型的泛化能力。交叉驗證:k折交叉驗證:將數據集分成k個子集,輪流使用每個子集作為驗證集,其余作為訓練集。**終結果是k次驗證的平均性能。留一交叉驗證:每次只留一個樣本作為驗證集,其余樣本作為訓練集,適用于小數據集。很多情況下,可以把模型檢測和各種抽象與歸納原則結合起來驗證非有窮狀態系統(如實時系統)。寶山區正規驗證模型優勢
將數據集分為訓練集和測試集,通常按70%/30%或80%/20%的比例劃分。嘉定區正規驗證模型優勢
交叉驗證(Cross-validation)主要用于建模應用中,例如PCR、PLS回歸建模中。在給定的建模樣本中,拿出大部分樣本進行建模型,留小部分樣本用剛建立的模型進行預報,并求這小部分樣本的預報誤差,記錄它們的平方加和。在使用訓練集對參數進行訓練的時候,經常會發現人們通常會將一整個訓練集分為三個部分(比如mnist手寫訓練集)。一般分為:訓練集(train_set),評估集(valid_set),測試集(test_set)這三個部分。這其實是為了保證訓練效果而特意設置的。其中測試集很好理解,其實就是完全不參與訓練的數據,**用來觀測測試效果的數據。而訓練集和評估集則牽涉到下面的知識了。嘉定區正規驗證模型優勢
上海優服優科模型科技有限公司在同行業領域中,一直處在一個不斷銳意進取,不斷制造創新的市場高度,多年以來致力于發展富有創新價值理念的產品標準,在上海市等地區的商務服務中始終保持良好的商業口碑,成績讓我們喜悅,但不會讓我們止步,殘酷的市場磨煉了我們堅強不屈的意志,和諧溫馨的工作環境,富有營養的公司土壤滋養著我們不斷開拓創新,勇于進取的無限潛力,上海優服優科模型科技供應攜手大家一起走向共同輝煌的未來,回首過去,我們不會因為取得了一點點成績而沾沾自喜,相反的是面對競爭越來越激烈的市場氛圍,我們更要明確自己的不足,做好迎接新挑戰的準備,要不畏困難,激流勇進,以一個更嶄新的精神面貌迎接大家,共同走向輝煌回來!
- 嘉定區銷售展示車加工要求 2025-06-02
- 普陀區銷售展示車加工訂制價格 2025-06-02
- 松江區智能汽車設計開發訂制價格 2025-06-02
- 長寧區正規展示車加工要求 2025-06-02
- 黃浦區正規汽車設計開發訂制價格 2025-06-02
- 徐匯區正規工程樣車試制大概是 2025-06-02
- 楊浦區銷售汽車設計開發要求 2025-06-02
- 虹口區直銷展示車加工供應 2025-06-02
- 靜安區自動展示車加工熱線 2025-06-02
- 奉賢區自動工程樣車試制信息中心 2025-06-02
- 靜安學校風機清洗技巧 2025-06-03
- 江北區請離婚律師費 2025-06-03
- 龍崗區飲料車間規劃時長 2025-06-03
- 龍巖真正的集成平臺 2025-06-03
- 公寓婁申商業廣場房貸 2025-06-03
- 附近陵園設計 2025-06-03
- FCT測試治具生產廠家 2025-06-03
- 泉州國內ipaas 2025-06-03
- 哈爾濱食品包裝材料檢測標準檢測 2025-06-03
- 連云港室內甲醛空氣檢測服務哪家服務好 2025-06-03